New in 1.3.6: Namespaces
Posted by Nick Johnson | Filed under python, app-engine, coding, namespaces
The recently released 1.3.6 update for App Engine introduces a number of exciting new features, including multi-tenancy - the ability to shard your app for multiple independent user groups - using a new Namespaces API. Today, we'll take a look at the Namespaces API and how it works.
One common question from people designing multi-tenant apps is how to charge users based on usage. While I'd normally recommend a simpler charging model, such as per user, that isn't universally applicable, and even when it is, it can be useful to keep track on just how much quota each tenant is consuming. Since multi-tenant apps just got a whole pile easier, we'll use this as an opportunity to explore per-tenant accounting options, too.
First up, let's take a look at the basic setup for namespacing. You can check out this demo for an example of what a fully featured, configurable namespace setup looks like, but presuming we want to use domain names as our namespaces, here's the simplest possible setup:
def namespace_manager_default_namespace_for_request(): import os return os.environ['SERVER_NAME']
That's all there is to it. If we wanted to switch on Google Apps domain instead ...
Using BlobReader, wildcard subdomains and webapp2
Posted by Nick Johnson | Filed under app-engine, python, coding, blobstore, blobreader, webapp2
Today we'll demonstrate a number of new features and libraries in App Engine, using a simple demo app. First and foremost, we'll be demonstrating BlobReader, which lets you read Blobstore blobs just as you would a local file, but we'll also be trying out two other shinies: Wildcard subdomains, which allow users to access your app as anything.yourapp.appspot.com (and now, anything.yourapp.com), and Moraes' excellent new webapp2 library, a drop-in replacement for the webapp framework.
Moraes has built webapp2 to be as compatible with the existing webapp framework as possible, while improving a number of things. Improvements include an enhanced response object (based on the one in webob), better routing support, support for 'status code exceptions', and URL generation support. While the app we're writing doesn't require any of these, per-se, it's a good opportunity to give webapp2 a test drive and see how it performs.
But what are we writing, you ask? Well, to show off just how useful BlobReader is, I wanted something that demonstrates how you can use it practically anywhere you can use a 'real' file object - such as using it to read zip files from ...
Damn Cool Algorithms: Levenshtein Automata
Posted by Nick Johnson | Filed under python, tech, coding, damn-cool-algorithms
In a previous Damn Cool Algorithms post, I talked about BK-trees, a clever indexing structure that makes it possible to search for fuzzy matches on a text string based on Levenshtein distance - or any other metric that obeys the triangle inequality. Today, I'm going to describe an alternative approach, which makes it possible to do fuzzy text search in a regular index: Levenshtein automata.
Introduction
The basic insight behind Levenshtein automata is that it's possible to construct a Finite state automaton that recognizes exactly the set of strings within a given Levenshtein distance of a target word. We can then feed in any word, and the automaton will accept or reject it based on whether the Levenshtein distance to the target word is at most the distance specified when we constructed the automaton. Further, due to the nature of FSAs, it will do so in O(n) time with the length of the string being tested. Compare this to the standard Dynamic Programming Levenshtein algorithm, which takes O(mn) time, where m and n are the lengths of the two input words! It's thus immediately apparrent that Levenshtein automaton provide, at a minimum, a faster way for ...
Getting unicode right in Python
Posted by Nick Johnson | Filed under python, text, unicode, rant
Yup, I'm back from holidays! Apologies to everyone for the delayed return - it's taking me a long while to catch up on everything that built up while I was away.
Proper text processing - specifically, correct handling of unicode - is one of those things that consistently confounds even experienced developers. This isn't because it's difficult, but rather, I believe, because most developers carry around a few key misconceptions about what text (in the context of software) is and how it's represented. A search on StackOverflow for UnicodeDecodeError demonstrates just how prevalent these misconceptions are. These misconceptions date back to the days before unicode - longer than many developers have been in the industry, including myself - but they're still nothing if not widespread. This is in part because a number of well known and popular languages continue to, at worst, perpetuate the misunderstandings, and at best are insufficiently good at helping developers get it right.
We can divide languages into four categories along the axis of unicode support:
- Languages that were written before unicode was defined, or widespread. C and C++ fall into this category. Languages in this category tend to have unicode support that's spotty ...
Using Python magic to improve the deferred API
Posted by Nick Johnson | Filed under python, deferred, app-engine, coding, celery
Recently, my attention was drawn, via a blog post to a Python task queue implementation called Celery. The object of my interest was not so much Celery itself - though it does look both interesting and well written - but the syntax it uses for tasks.
While App Engine's deferred library takes the 'higher level function' approach - that is, you pass your function and its arguments to the 'defer' function - I've never been entirely happy with that approach. Celery, in contrast, uses Python's support for decorators (one of my favorite language features) to create what, in my view, is a much neater and more flexible interface. While defining and calling a deferred function looks like this:
def my_task_func(some_arg): # do something defer(my_task_func, 123)
Doing the same in Celery looks like this:
@task def my_task_func(some_arg): # do something my_task_func.delay(123)
Using a decorator, Celery is able to modify the function it's decorating such that you can now call it on the task queue using a much more intuitive syntax, with the function's original calling convention preserved. Let's take a look at how this works, first, and then explore how we might make use of it ...
Guessing subreddits with the Prediction API
Posted by Nick Johnson | Filed under python, app-engine, prediction-api, google-storage
Edit: Now with a live demo!
I've written before about the new BigQuery and Prediction APIs, and promised to demonstrate them. Let's take a look at the Prediction API first.
The Prediction API, as I've explained, does a restricted form of machine learning, as a web service. Currently, it supports categorizing textual and numeric data into a preset list of categories. The example given in the talk - language detection - is a good one, but I wanted to come up with something new. A few ideas presented themselves:
- Training on movie/book reviews to try and predict the score given based on the text
- Training on product descriptions to try and predict their rating
- Training on Reddit submissions to try and predict the subreddit a new submission belongs in
All three have promise, but the first could suffer from the fact that the prediction API as it currently stands doesn't understand a relationship between categories - it would have no way to know that the '5 star' rating tag is 'closer to' the '4 star' one than the '1 star' tag. The second seems very ambitious, and it's not clear there's enough information to do that ...
Using remote_api with OpenID authentication
Posted by Nick Johnson | Filed under python, openid, app-engine, remote-api
When we recently released integrated OpenID support for App Engine, one unfortunate side-effect for apps that enable it was disruption to authenticated, programmatic access to your App Engine app. Specifically, if you've switched your app to use OpenID for authentication, remote_api - and the remote_api console - will no longer work.
The bad news is that fixing this is tough: OpenID is designed as a browser-interactive authentication mechanism, and it's not clear what the best way to do authentication for command line tools like the remote_api console is going to be. Quite likely the solution will involve our OAuth support and stored credentials - stay tuned!
The good news, though, is that there's a workaround that you can use right now, without compromising the security of your app. It's a bit of a hack, though, so brace yourself!
The essential insight behind the hack is that if we can trick the SDK into thinking that it's authenticating against the development server instead of production, it will prompt the user for an email address and password, then send that email address embedded in the 'dev_appserver_login' cookie with all future requests. We can then use the email field to instead ...
Using OpenID authentication on App Engine
Posted by Nick Johnson | Filed under python, openid, app-engine, coding, clickpass
With the release of SDK 1.3.4, preliminary support is available for native OpenID authentication in App Engine. Today, we'll demonstrate how to use the new OpenID support in your app.
Edit: There's now an official article on OpenID on App Engine!
The first step in setting up OpenID authentication is to change your app's authentication settings. Log in to the admin console, select your app, and go to "Application Settings". There, you can pull down the "Authentication Options" box, and select "(Experimental) Federated Login".
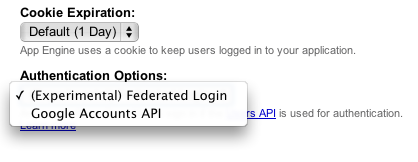
Once you've enabled OpenID authentication for your app, a few things change:
- URLs generated by create_login_url without a federated_identity parameter specified will redirect to the OpenID login page for Google Accounts.
- URLs that are protected by "login: required" in app.yaml or web.xml will result in a redirect to the path "/_ah/login_required", with a "continue" parameter of the page originally fetched. This allows you to provide your own openid login page.
- URLs generated by create_login_url with a federated_identity provider will redirect to the specified provider.
In order to make best use of this functionality, here's what we'll do:
- Provide an OpenID login page on /_ah/login_required ...
Behind the scenes with remote_api
Posted by Nick Johnson | Filed under python, remote_api, app-engine, internals
I've discussed remote_api in passing many times before on this blog, but never gone into detail about how it works, and the options you have for customizing it. Today, we'll remedy that, by taking a close look at its operation.
You may be wondering why anyone would want to customize remote_api - it seems like a fairly straightforward service, right? There are two main reasons you might want to do some degree of customization:
- You're providing a software-as-a-service solution, and need to provide remote_api access to your customers, but want to limit what they can do.
- You want to expose an API of your own via remote_api.
The first of these use-cases is particularly apt in the face of this nasty hack, which makes it possible to download a Python app's source if both the remote_api and deferred handlers are installed (and the user is an admin). You may want to use both of these libraries, but still keep your source to yourself. The second use-case is more complicated, and we'll only touch on it in passing.
How remote_api works
remote_api has two components, the client (otherwise known as the 'stub') and the server (otherwise known ...
App Engine Cookbook: On-demand Cron Jobs
Posted by Nick Johnson | Filed under python, coding, app-engine, cookbook, tech
Today's post is, by necessity, a brief one. I'm travelling to San Francisco for I/O at the moment, and my flight was delayed so much I missed my connection in Atlanta and had to stay the night; in fact, I'm writing and posting this from the plane, using the onboard WiFi!
In a previous post, I introduced a recipe for high concurrency counters, which used a technique that I believe deserves its own post, since it's a useful pattern on its own. That technique is what I'm calling "On-demand Cron Jobs"
It's not at all uncommon for apps to have a need to do periodic updates at intervals, where the individual updates are small, and may even shift in time. One example is deleting or modifying any entry that hasn't been modified in the last day. In apps that need to do this, it's not uncommon to see a cron job like the following:
cron: - description: Clean up old data url: /tasks/cleanup schedule: every 1 minute
This works, but it potentially consumes a significant amount of resources checking repeatedly if there's anything to clean up. Using the task queue ...
Newer Older