Under the hood with App Engine APIs
Posted by Nick Johnson | Filed under python, app-engine, coding, datastore
In the past, I've discussed various details of the way various App Engine APIs work under the hood. If you've used certain tools, such as Appstats, too, you probably already have a basic overview of how the App Engine APIs function. Today, we'll take a closer look at the interface between the App Engine runtime and its APIs and how it works, and learn what that means for the platform.
If you're interested in App Engine purely to write straightforward webapps, you can probably stop reading now. If you're interested in low-level optimisations, or in the platform itself, or you want to write a library or tool that tinkers with the innermost parts of App Engine, then read on!
The generic API interface
Ultimately, every API call comes down to a single generic interface, with 4 arguments: the service name (for example, 'datastore_v3' or 'memcache'), the method name (for example, 'Get' or 'RunQuery'), the request, and the response. The request and response components are both Protocol Buffers, a binary format widely used at Google for exchanging structured data between processes. The specific type of the request and response protocol buffers for an API call depend ...
New in 1.3.6: Namespaces
Posted by Nick Johnson | Filed under python, app-engine, coding, namespaces
The recently released 1.3.6 update for App Engine introduces a number of exciting new features, including multi-tenancy - the ability to shard your app for multiple independent user groups - using a new Namespaces API. Today, we'll take a look at the Namespaces API and how it works.
One common question from people designing multi-tenant apps is how to charge users based on usage. While I'd normally recommend a simpler charging model, such as per user, that isn't universally applicable, and even when it is, it can be useful to keep track on just how much quota each tenant is consuming. Since multi-tenant apps just got a whole pile easier, we'll use this as an opportunity to explore per-tenant accounting options, too.
First up, let's take a look at the basic setup for namespacing. You can check out this demo for an example of what a fully featured, configurable namespace setup looks like, but presuming we want to use domain names as our namespaces, here's the simplest possible setup:
def namespace_manager_default_namespace_for_request(): import os return os.environ['SERVER_NAME']
That's all there is to it. If we wanted to switch on Google Apps domain instead ...
Using BlobReader, wildcard subdomains and webapp2
Posted by Nick Johnson | Filed under app-engine, python, coding, blobstore, blobreader, webapp2
Today we'll demonstrate a number of new features and libraries in App Engine, using a simple demo app. First and foremost, we'll be demonstrating BlobReader, which lets you read Blobstore blobs just as you would a local file, but we'll also be trying out two other shinies: Wildcard subdomains, which allow users to access your app as anything.yourapp.appspot.com (and now, anything.yourapp.com), and Moraes' excellent new webapp2 library, a drop-in replacement for the webapp framework.
Moraes has built webapp2 to be as compatible with the existing webapp framework as possible, while improving a number of things. Improvements include an enhanced response object (based on the one in webob), better routing support, support for 'status code exceptions', and URL generation support. While the app we're writing doesn't require any of these, per-se, it's a good opportunity to give webapp2 a test drive and see how it performs.
But what are we writing, you ask? Well, to show off just how useful BlobReader is, I wanted something that demonstrates how you can use it practically anywhere you can use a 'real' file object - such as using it to read zip files from ...
Damn Cool Algorithms: Levenshtein Automata
Posted by Nick Johnson | Filed under python, tech, coding, damn-cool-algorithms
In a previous Damn Cool Algorithms post, I talked about BK-trees, a clever indexing structure that makes it possible to search for fuzzy matches on a text string based on Levenshtein distance - or any other metric that obeys the triangle inequality. Today, I'm going to describe an alternative approach, which makes it possible to do fuzzy text search in a regular index: Levenshtein automata.
Introduction
The basic insight behind Levenshtein automata is that it's possible to construct a Finite state automaton that recognizes exactly the set of strings within a given Levenshtein distance of a target word. We can then feed in any word, and the automaton will accept or reject it based on whether the Levenshtein distance to the target word is at most the distance specified when we constructed the automaton. Further, due to the nature of FSAs, it will do so in O(n) time with the length of the string being tested. Compare this to the standard Dynamic Programming Levenshtein algorithm, which takes O(mn) time, where m and n are the lengths of the two input words! It's thus immediately apparrent that Levenshtein automaton provide, at a minimum, a faster way for ...
Using Python magic to improve the deferred API
Posted by Nick Johnson | Filed under python, deferred, app-engine, coding, celery
Recently, my attention was drawn, via a blog post to a Python task queue implementation called Celery. The object of my interest was not so much Celery itself - though it does look both interesting and well written - but the syntax it uses for tasks.
While App Engine's deferred library takes the 'higher level function' approach - that is, you pass your function and its arguments to the 'defer' function - I've never been entirely happy with that approach. Celery, in contrast, uses Python's support for decorators (one of my favorite language features) to create what, in my view, is a much neater and more flexible interface. While defining and calling a deferred function looks like this:
def my_task_func(some_arg): # do something defer(my_task_func, 123)
Doing the same in Celery looks like this:
@task def my_task_func(some_arg): # do something my_task_func.delay(123)
Using a decorator, Celery is able to modify the function it's decorating such that you can now call it on the task queue using a much more intuitive syntax, with the function's original calling convention preserved. Let's take a look at how this works, first, and then explore how we might make use of it ...
Using OpenID authentication on App Engine
Posted by Nick Johnson | Filed under python, openid, app-engine, coding, clickpass
With the release of SDK 1.3.4, preliminary support is available for native OpenID authentication in App Engine. Today, we'll demonstrate how to use the new OpenID support in your app.
Edit: There's now an official article on OpenID on App Engine!
The first step in setting up OpenID authentication is to change your app's authentication settings. Log in to the admin console, select your app, and go to "Application Settings". There, you can pull down the "Authentication Options" box, and select "(Experimental) Federated Login".
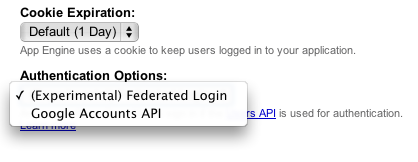
Once you've enabled OpenID authentication for your app, a few things change:
- URLs generated by create_login_url without a federated_identity parameter specified will redirect to the OpenID login page for Google Accounts.
- URLs that are protected by "login: required" in app.yaml or web.xml will result in a redirect to the path "/_ah/login_required", with a "continue" parameter of the page originally fetched. This allows you to provide your own openid login page.
- URLs generated by create_login_url with a federated_identity provider will redirect to the specified provider.
In order to make best use of this functionality, here's what we'll do:
- Provide an OpenID login page on /_ah/login_required ...
Exploring the new mapper API
Posted by Nick Johnson | Filed under app-engine, google-io, coding, mapreduce
One of the new features announced at this year's Google I/O is the new mapper library. This library makes it easy to perform bulk operations on your data, such as updating it, deleting it, or transforming/filtering/processing it in some fashion, using the 'map' (and soon, 'reduce') pattern. I'm happy to say that I'm deprecating my own bulkupdate library in favor of it.
The mapper API isn't just limited to mapping over datastore entities, either. You can map over lines in a text file in the blobstore, or over the contents of a zip file in the blobstore. It's even possible to write your own data sources - something we'll cover in a later post. Today, though, I'd like to dissect the demo that was presented at I/O. The demo uses a number of the mapper framework's more sophisticated features, so it's a good one to use to get an idea for how the framework works.
For basic usage, the Getting Started page in the mapper docs is the place to go. If you're interested in seeing something more complex in practice, read on...
The demo at I ...
Help me name my distributed publishing system
Posted by Nick Johnson | Filed under censorship-resistant, dht, coding
A few days ago, I posted an outline for a distributed publishing system. I asked for name suggestions, and people have provided more than a few!
Here's the shortlist. Please vote on the one you think works best, or suggest your own.
App Engine Cookbook: On-demand Cron Jobs
Posted by Nick Johnson | Filed under python, coding, app-engine, cookbook, tech
Today's post is, by necessity, a brief one. I'm travelling to San Francisco for I/O at the moment, and my flight was delayed so much I missed my connection in Atlanta and had to stay the night; in fact, I'm writing and posting this from the plane, using the onboard WiFi!
In a previous post, I introduced a recipe for high concurrency counters, which used a technique that I believe deserves its own post, since it's a useful pattern on its own. That technique is what I'm calling "On-demand Cron Jobs"
It's not at all uncommon for apps to have a need to do periodic updates at intervals, where the individual updates are small, and may even shift in time. One example is deleting or modifying any entry that hasn't been modified in the last day. In apps that need to do this, it's not uncommon to see a cron job like the following:
cron: - description: Clean up old data url: /tasks/cleanup schedule: every 1 minute
This works, but it potentially consumes a significant amount of resources checking repeatedly if there's anything to clean up. Using the task queue ...
Building a censorship resistant publishing system
Posted by Nick Johnson | Filed under coding, censorship-resistant, dht, tech
I've had an idea related to censorship resistant publishing kicking around in my head for some time now, and it seems like it's about time I got it written down somewhere, for consideration and criticism. Part of my motivation is that I'm intending to snatch some spare time while I'm on the plane to the US this weekend (to attend I/O) to have a go at implementing a basic version of it.
In a nutshell, I have a design for what I believe would be a fairly robust censorship resistant publishing system, based on a DHT, and integrating fully with the web. Content published using this system would be available in exactly the same fashion as a regular website, which strikes me as a major advantage over many other proposals for similar systems.
The system consists of several layers, which I'll tackle in order:
- Document storage and retrieval
- Name resolution for documents within a 'site'
- External access
- Name resolution for sites
Document storage and retrieval
The lowest level of the system is also the simplest: That of storing and retrieving documents. This layer of the system acts more or less exactly like a regular ...
Older